成長株投資でバイブル的に有名な本を出版されているミネルヴィニ氏曰く、成長株投資には四半期の増益率を重視すべきだそうです。
本記事では、この条件に当てはまる株を探すために、EDINETとpythonを活用して任意の企業の四半期営業利益や入手する方法の紹介となります。
買いの候補は、直前の四半期だけでなく、過去2~4四半期の利益もかなり伸びている会社に絞るべきだ。(中略)成長株投資で成功しているマネージャーの多くは、過去2~4四半期に、前年同期比で最低でも20~25%の増益率を条件にしている。増益率が大きいほど望ましい。本当に成長している会社はたいてい、急成長期に30~40%以上の増益を発表する。
引用元:ミネルヴィニの成長株投資法 P.161

2020/08/29 有価証券報告書の入手など色々な不足分を追加しました。
社長の持ち株比率を抽出する記事を作成しました。

手順の概要
指定した期間・報告書種類(四半期決算報告書、有価証券報告書)・会社の営業利益を、以下のような手順で入手します。
コードの全体は記事の最下部に記載しています。
- EDINETから任意の書類のコードリストを入手する
- コードリストを使用してEDINETから任意の書類をzipでDLする
- zipからXBRLを読込んで、pandasのデータフレーム形式に変換する
- データフレームから各四半期の営業利益を抽出する
EDINETから任意の書類のコードリストを入手
get_list関数に、任意の会社名や取得期間、保存場所を与えます。
get_list関数ではEDINETのAPIを活用して、任意の書類のコードリストを入手します。
EDINETには、各日に提出された書類の情報を返すAPIが用意されています。
得られたリストの中から、四半期報告書や有価証券報告書を表すコードを活用して、必要な書類のリストを作成しています。
#データ抜出時に使用する、有価証券報告書および四半期報告書のコードの設定
ordinance_code = "010"
form_code_quart ="043000" # 四半期報告書
form_code_securities ="030000" #有価証券報告書EDINETのAPIに関しては以下のリンク先に、必要な事項について分かりやすくまとめられていました。

書類のコードリストを活用してzipファイルをダウンロードする
get_list関数で得た書類のIDを活用して、get_zip関数でzipファイルをDLしています。
DLしたzipファイルからXBRLを読込んで、pandasのデータフレーム形式に変換する
XBRLファイルを自身で整形するのはかなりの労力を要するため、先人に作製していただいたライブラリを活用します。
導入方法などは、本家のサイトを参照ください。

このライブラリを使用すると、XBRLを以下のようなpandasデータフレームの形式に変換することが可能です。

zip_to_df関数により、このライブラリを使用して各zipファイルから以下のような[書類タイプ][会社名][データフレーム]の構造を有する辞書が返されます。
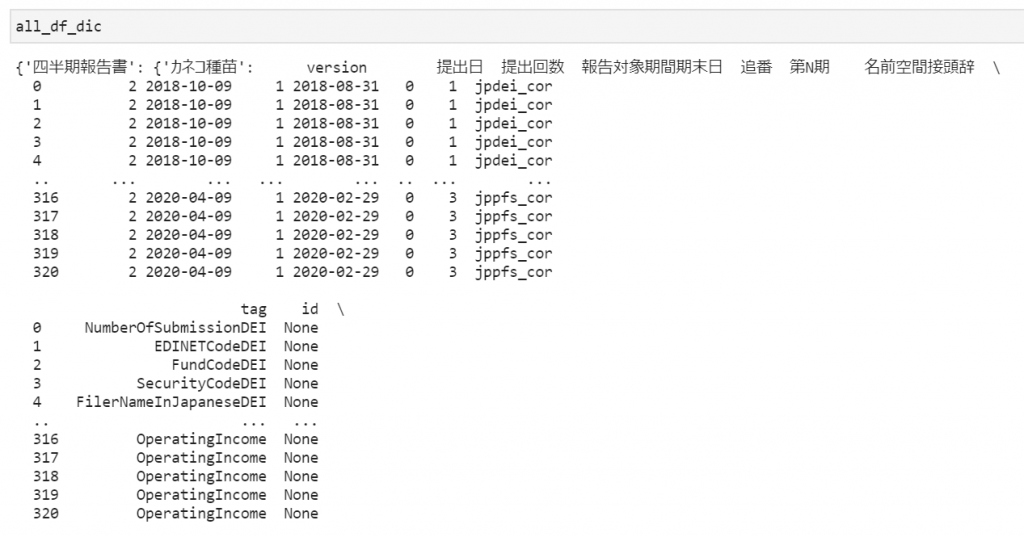
データフレームから各四半期の営業利益を抽出する
上記ライブラリを活用して得たデータフレームの「tag」と「context」の列から条件を絞り、営業利益を抽出します。
営業利益を表すtagの「OperatingIncome」と、期間を指定するcontext(四半期報告書では、「CurrentYTDDuration」、有価証券報告書では、「CurrentYearDuration」)から営業利益の抽出が可能です。
「終了日」から各期を特定できそうです。
2020/9/13 追記
連結非連結によってcontextが変わるようです。
連結財務諸表を表す場合は、シナリオ要素に「ConsolidatedMember」を設定しません。
個別財務諸表を表す場合は、シナリオ要素に「NonConsolidatedMember」を設定します
金融庁 報告書インスタンス 作成ガイドライン
# 営業利益部分抽出
quart = all_df_dic['四半期報告書']['カネコ種苗']
quart_oi = quart[(quart['tag'] == 'OperatingIncome') & (quart['context'] == 'CurrentYTDDuration')]
quart_oi = quart_oi[['第N期','終了日','値']].sort_values('終了日')
quart_oi = quart_oi.rename({'終了日':'Date','値':'OperatingIncome'},axis=1).reset_index(drop=True)
quart_oi['type'] = '四半期報告書'
securities = all_df_dic['有価証券報告書']['カネコ種苗']
securities_oi = securities[(securities['tag'] == 'OperatingIncome') & (securities['context'] == 'CurrentYearDuration')]
securities_oi = securities_oi[['第N期','終了日','値']].sort_values('終了日')
securities_oi = securities_oi.rename({'終了日':'Date','値':'OperatingIncome'},axis=1).reset_index(drop=True)
securities_oi['type'] = '有価証券報告書'
oi_df = pd.concat([quart_oi,securities_oi]).sort_values('Date').reset_index(drop=True)抽出したデータ
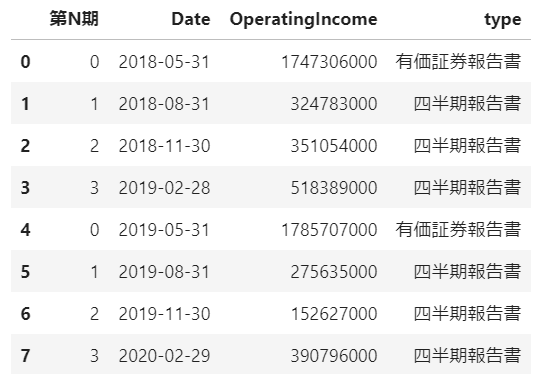
各期ごとの営業利益を計算して可視化する
上記のような方法で各報告書から抽出しただけの営業利益は、累積値となっています。
従って、各期ごとの値を得るために、前期までの累積値を差し引く以下のような計算を行っています。
# 各四半期ごとの営業利益や、前年同期比の売上高営業利益率の変化を計算
oi_df['tempOperatingIncome'] = oi_df['OperatingIncome'] - oi_df['OperatingIncome'].shift(1)
oi_df['CalcOperatingIncome'] = oi_df['OperatingIncome'].mask(oi_df['第N期'] == 0, oi_df['tempOperatingIncome'])
oi_df['CalcOperatingIncome'] = oi_df['CalcOperatingIncome'].mask(oi_df['第N期'] == 3, oi_df['tempOperatingIncome'])
oi_df['CalcOperatingIncome'] = oi_df['CalcOperatingIncome'].mask(oi_df['第N期'] == 2, oi_df['tempOperatingIncome'])
oi_df['CalcOperatingIncome_YoYchangerate'] = oi_df['CalcOperatingIncome'] / oi_df['CalcOperatingIncome'].shift(4)
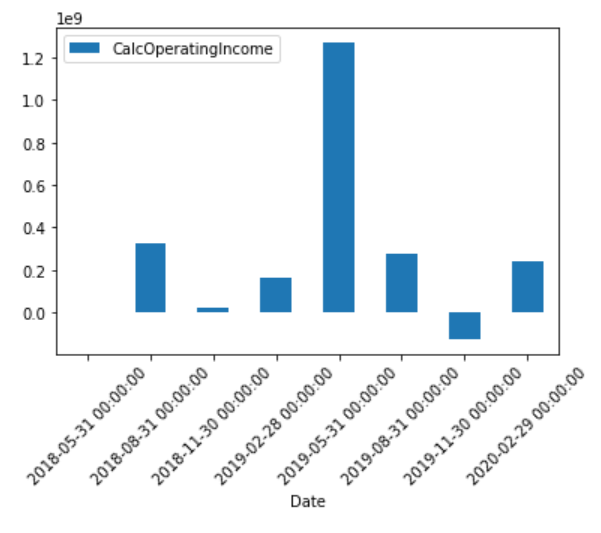
各期ごとに計算しなおした営業利益
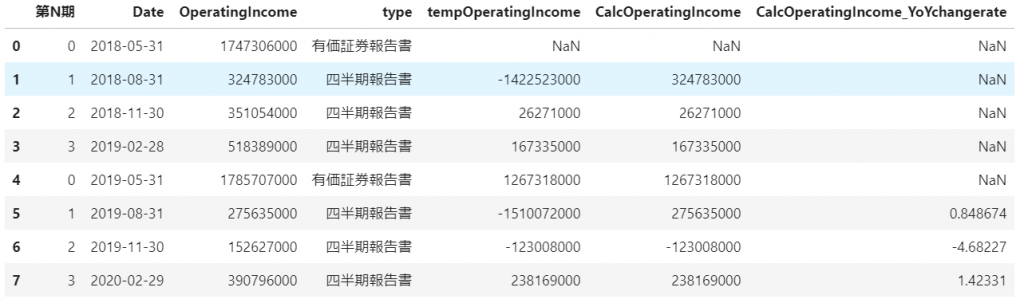
各期ごとの営業利益
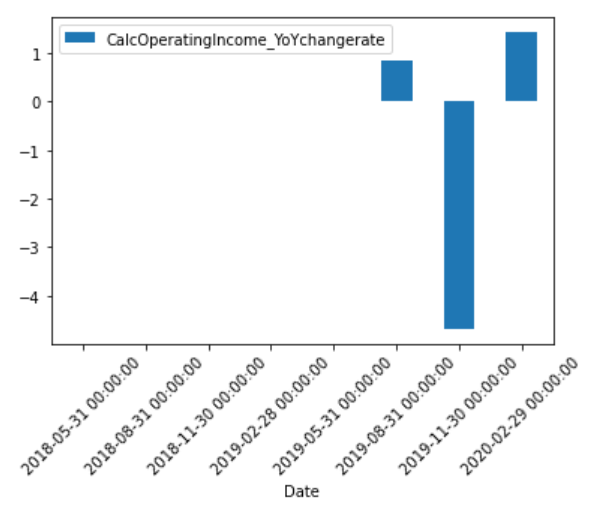
前年同期比の営業利益率変化
全コード
from datetime import date,timedelta
import requests
import json
from zipfile import ZipFile
import os
import sys
import pandas as pd
import glob
# XBRLをpython形式に変換するライブラリのフォルダパス
sys.path.append(r'任意のフォルダパス')
from xbrl_proc import read_xbrl_from_zip
import urllib3
from urllib3.exceptions import InsecureRequestWarning
urllib3.disable_warnings(InsecureRequestWarning)
def get_list(start,end,company_list):
'''指定した期間、報告書種類、会社で報告書を取得し、取得したファイルのパスの辞書を返す'''
#取得期間の日付リストを作成
day_term = [start + timedelta(days=i) for i in range((end - start).days)]
#データ抜出時に使用する、有価証券報告書および四半期報告書のコードの設定
ordinance_code = "010"
form_code_quart ="043000" # 四半期報告書
form_code_securities ="030000" #有価証券報告書
# EDINETのAPIで、書類一覧を取得し、各日ごとに必要な書類の項目を抜き出し
quart_list =[] # 四半期報告書のリスト
securities_list =[] # 四半期報告書のリスト
print('EDINETへのアクセスを開始')
for i,day in enumerate(day_term):
url = "https://disclosure.edinet-fsa.go.jp/api/v1/documents.json"
params = {"date": day, "type": 2}
# 進捗表示
if i % 50 == 0:
print(f'{i}日目:{day}を開始')
# EDINETから1日の書類一覧を取得
res = requests.get(url, params=params, verify=False)
# 必要な書類の項目を抜き出し
if res.ok:
json_data = res.json()
for data in json_data['results']:
# 指定した会社の指定した書類を抜き出し
if data['ordinanceCode'] == ordinance_code and data['formCode'] == form_code_quart and data['filerName'].replace('株式会社', '') in company_list:
quart_list.append(data)
elif data['ordinanceCode'] == ordinance_code and data['formCode'] == form_code_securities and data['filerName'].replace('株式会社', '') in company_list:
securities_list.append(data)
else:
print(f'アクセス失敗かも{day}')
list_dic = {'四半期報告書':quart_list,'有価証券報告書':securities_list}
return list_dic
def get_zip(list_dic,quart_dir_path,securities_dir_path):
'''取得したいデータをzipファイルで取得してファイルパスのリストを返す'''
dir_path_dic = {'四半期報告書':quart_dir_path,'有価証券報告書':securities_dir_path}
file_path_dic = {'四半期報告書':[],'有価証券報告書':[]} # ダウンロードした有価証券報告書のパスを格納する辞書
for key in list_dic.keys():
# すでにzipをDLしている場合のため、既存のdocIDリストを取得
files = os.listdir(dir_path_dic[key])
existing_docID_list = [file.split('.')[0].split('_')[1] for file in files if os.path.isfile(os.path.join(dir_path_dic[key], file))]
print(f'{key}ファイルのDLを開始')
for i, doc in enumerate(list_dic[key]):
# zipファイルパスのリストの作成
file_name = doc['filerName'].replace('株式会社', '') + '_' + doc['docID']
file_path = os.path.join(dir_path_dic[key], file_name + ".zip")
file_path_dic[key].append(file_path)
# 所有していないファイルの場合はDLを行う
if doc['docID'] not in existing_docID_list:
# ファイルを取得
url_zip = "https://disclosure.edinet-fsa.go.jp/api/v1/documents/" + doc['docID']
params_zip = {"type": 1}
# 進捗表示
if i % 100 == 0:
print(f'{i}ファイル目を開始')
# データのDL
res_zip = requests.get(url_zip, params=params_zip, verify=False, stream=True)
# zipとして保存
if res_zip.status_code == 200:
with open(file_path, 'wb') as f:
for chunk in res_zip.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
f.flush()
return file_path_dic
def zip_to_df(file_path_dic):
'''ダウンロードしたzipをdfに変換して各会社のdicにして返す'''
all_df_dic = {}
for key in file_path_dic.keys():
print(f'{key}データの変換を開始')
df_dic = {}
for i,company_zip in enumerate(file_path_dic[key]):
# 進捗表示
if i % 100 == 0:
print(f'{i}ファイル目を開始')
company_name = os.path.splitext(os.path.basename(company_zip))[0].split('_')[0]
doc_name = os.path.splitext(os.path.basename(company_zip))[0].split('_')[1]
if company_name not in df_dic:# 会社が辞書中に存在しない場合
df_dic[company_name] = {}
df_dic[company_name] = read_xbrl_from_zip(company_zip)[0]
elif company_name in df_dic:# 会社が辞書中に存在する場合
df_dic[company_name] = pd.concat( [df_dic[company_name],read_xbrl_from_zip(company_zip)[0]])
all_df_dic[key] = df_dic
return all_df_dic
# 会社のリストを読み込み
company_list = ['ホウスイ','カネコ種苗']
# 取得期間の設定:直近n日分
delta_day = 800
end = date.today()
start = date.today() - timedelta(days=delta_day)
# ダウンロードしたデータのフォルダパス
quart_dir_path = r'四半期報告書を保存する任意のフォルダパス'
securities_dir_path = r'有価証券報告書を保存する任意のフォルダパス'
# XBRLデータの取得
list_dic = get_list(start,end,company_list)
file_path_dic = get_zip(list_dic,quart_dir_path,securities_dir_path)
# XBRLからデータ形式を変換
df_dic = zip_to_df(file_path_list)
# 営業利益部分抽出
quart = all_df_dic['四半期報告書']['カネコ種苗']
quart_oi = quart[(quart['tag'] == 'OperatingIncome') & (quart['context'] == 'CurrentYTDDuration')]
quart_oi = quart_oi[['第N期','終了日','値']].sort_values('終了日')
quart_oi = quart_oi.rename({'終了日':'Date','値':'OperatingIncome'},axis=1).reset_index(drop=True)
quart_oi['type'] = '四半期報告書'
securities = all_df_dic['有価証券報告書']['カネコ種苗']
securities_oi = securities[(securities['tag'] == 'OperatingIncome') & (securities['context'] == 'CurrentYearDuration')]
securities_oi = securities_oi[['第N期','終了日','値']].sort_values('終了日')
securities_oi = securities_oi.rename({'終了日':'Date','値':'OperatingIncome'},axis=1).reset_index(drop=True)
securities_oi['type'] = '有価証券報告書'
oi_df = pd.concat([quart_oi,securities_oi]).sort_values('Date').reset_index(drop=True)
# 各四半期ごとの営業利益や、前年同期比の売上高営業利益率の変化を計算
oi_df['tempOperatingIncome'] = oi_df['OperatingIncome'] - oi_df['OperatingIncome'].shift(1)
oi_df['CalcOperatingIncome'] = oi_df['OperatingIncome'].mask(oi_df['第N期'] == 0, oi_df['tempOperatingIncome'])
oi_df['CalcOperatingIncome'] = oi_df['CalcOperatingIncome'].mask(oi_df['第N期'] == 3, oi_df['tempOperatingIncome'])
oi_df['CalcOperatingIncome'] = oi_df['CalcOperatingIncome'].mask(oi_df['第N期'] == 2, oi_df['tempOperatingIncome'])
oi_df['CalcOperatingIncome_YoYchangerate'] = oi_df['CalcOperatingIncome'] / oi_df['CalcOperatingIncome'].shift(4)
# 棒グラフで可視化
oi_df.plot.bar(x='Date', y='CalcOperatingIncome', rot=45)
oi_df.plot.bar(x='Date', y='CalcOperatingIncome_YoYchangerate', rot=45)
コメント