以下の本によると、成長株となるような会社は、その会社の社長がオーナーであるか否かが重要なポイントであるようです。
とはいえ、このような情報は株の銘柄スクリーニング機能として一般的には提供されていないようでした。
有価証券報告書には社長名と主要株主リストが記載されています。
本記事では、EDINETから有価証券報告書の入手と、社長及び株主情報の抽出をプログラムで行ってみた際の処理手順について紹介します。

会社四季報の達人が教える10倍株・100倍株の探し方
20年以上、毎号2000ページ超の会社四季報を 長編小説のように読んだ達人が教える お宝株、大化け株が見つかる! 四季報を使った10倍株(テンバガー)、100倍株を見つける原則を解説しています。過去の四季報の誌面を使用して、原則や方法を検証し、実践的な見つけ方を解説しているので、四季報のどこを見れば、10倍株・100倍...
www.amazon.co.jp
プログラムの流れ
プログラムの全体は、記事の最下部に記載しています。
オーナー企業か否かの判定をするために、以下のような処理を行いました。
- 企業のEDINETコードと証券コードの一覧のcsvを読込む
- 証券会社から入手した調査したい企業の銘柄コードが記載されたcsvファイルを読込む
- 1.2.のファイルを結合し、調査したい企業のEDINETコードリストを作成する
- EDINETのAPIを活用し、EDINETコードから有価証券報告書の文書コードリストを入手する(get_list関数)
- 文書コードリストとEDINETのAPIを用いて、有価証券報告書zipファイルをDLする(get_zip関数)
- zipからデータフレーム形式でデータを読込む(zip_to_df関数)
- 読込んだデータから株主情報を取得し、オーナー企業か否かを判定する(pickup_shareholder関数)
以下にプログラムの実行例を示します。
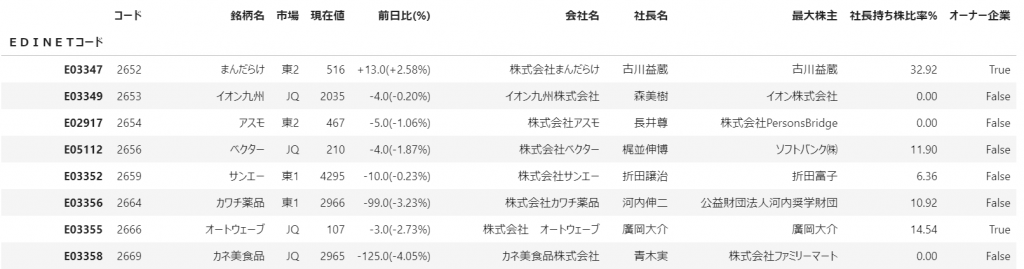
オーナー企業か否とその持ち株比率を取得できていそうです。
プログラムの実行結果例
処理1-3 について
手順1で使用している企業のEDINETコードと証券コードの一覧になっているcsvファイルは、リンク先(EDINET)の最下部に添付されているEDINETコードリストです。
以下のようなコードで、データフレームとして読み込んでいます。
code_company_df = pd.read_csv('EdinetcodeDlInfo.csv',header=1)
code_company_df = code_company_df.rename({'証券コード':'コード','提出者名':'会社名'},axis=1)
code_company_df = code_company_df[code_company_df['上場区分'] == '上場']
code_company_df['コード'] = code_company_df['コード']/10
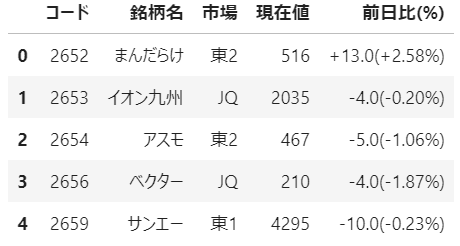
調査したい企業の銘柄コードは、証券会社のスクリーニング機能を使用して、以下のようなファイルとして準備しました。
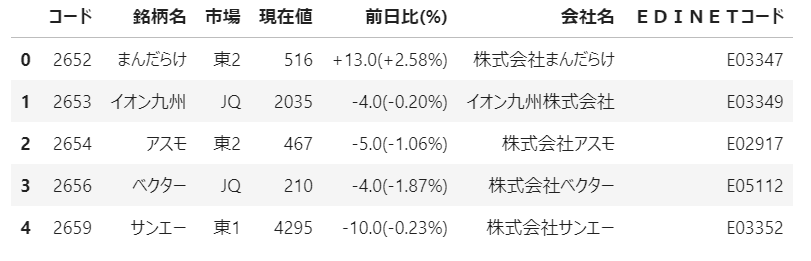
上記二つのファイルを結合して、以下のようなファイルにしています。
手順4-7について
以前の記事で、基本的なところは解説していますのでそちらを参照ください。

手順8 について
主要な株主をtag : NameMajorShareholdersdで、社長をtag : TitleAndNameOfRepresentativeCoverPageを使用して抽出しています。
コード全体
from datetime import date,timedelta
import requests
import json
from zipfile import ZipFile
import os
import sys
import pandas as pd
import glob
import numpy as np
# XBRLをpython形式に変換するライブラリのフォルダパス
sys.path.append(r'任意のフォルダパス')
from xbrl_proc import read_xbrl_from_zip
import urllib3
from urllib3.exceptions import InsecureRequestWarning
urllib3.disable_warnings(InsecureRequestWarning)
def get_list(start,end,company_df):
'''指定した期間、報告書種類、会社で報告書を取得し、取得したファイルのパスの辞書を返す'''
#取得期間の日付リストを作成
day_term = [start + timedelta(days=i) for i in range((end - start).days)]
# 会社コードリストを取得
company_list =list(company_df['EDINETコード'])
#データ抜出時に使用する、有価証券報告書および四半期報告書のコードの設定
ordinance_code = "010"
form_code_quart ="043000" # 四半期報告書
form_code_securities ="030000" #有価証券報告書
# EDINETのAPIで、書類一覧を取得し、各日ごとに必要な書類の項目を抜き出し
quart_list =[] # 四半期報告書のリスト
securities_list =[] # 四半期報告書のリスト
print('EDINETへのアクセスを開始')
for i,day in enumerate(day_term):
url = "https://disclosure.edinet-fsa.go.jp/api/v1/documents.json"
params = {"date": day, "type": 2}
# 進捗表示
if i % 50 == 0:
print(f'{i}日目:{day}を開始')
# EDINETから1日の書類一覧を取得
res = requests.get(url, params=params, verify=False)
# 必要な書類の項目を抜き出し
if res.ok:
json_data = res.json()
a = json_data['metadata']['status']
if int(a) == 200:
for data in json_data['results']:
# 指定した会社の指定した書類を抜き出し
name = None
if data['edinetCode'] is not None:
edinetCode = data['edinetCode']
if data['ordinanceCode'] == ordinance_code and data['formCode'] == form_code_quart and edinetCode in company_list:
quart_list.append(data)
elif data['ordinanceCode'] == ordinance_code and data['formCode'] == form_code_securities and edinetCode in company_list:
securities_list.append(data)
else:
print(f'エラー{day},{a}')
else:
print(f'アクセス失敗かも{day}')
list_dic = {'四半期報告書':quart_list,'有価証券報告書':securities_list}
return list_dic
def get_zip(list_dic,quart_dir_path,securities_dir_path):
'''取得したいデータをzipファイルで取得してファイルパスのリストを返す'''
dir_path_dic = {'四半期報告書':quart_dir_path,'有価証券報告書':securities_dir_path}
file_path_dic = {'四半期報告書':[],'有価証券報告書':[]} # ダウンロードした有価証券報告書のパスを格納する辞書
for key in list_dic.keys():
# すでにzipをDLしている場合のため、既存のdocIDリストを取得
files = os.listdir(dir_path_dic[key])
existing_docID_list = [file.split('.')[0].split('_')[2] for file in files if os.path.isfile(os.path.join(dir_path_dic[key], file))]
print(f'{key}ファイルのDLを開始')
for i, doc in enumerate(list_dic[key]):
# zipファイルパスのリストの作成
file_name = doc['filerName'].replace('株式会社', '').replace('ホールディングス','HLDG').replace('\xa0','').replace('\u3000','').replace('\n','').replace(' ','') + '_' + doc['edinetCode'] + '_' + doc['docID']
file_path = os.path.join(dir_path_dic[key], file_name + ".zip")
file_path_dic[key].append(file_path)
# 所有していないファイルの場合はDLを行う
if doc['docID'] not in existing_docID_list:
# ファイルを取得
url_zip = "https://disclosure.edinet-fsa.go.jp/api/v1/documents/" + doc['docID']
params_zip = {"type": 1}
# 進捗表示
if i % 100 == 0:
print(f'{i}ファイル目を開始')
# データのDL
res_zip = requests.get(url_zip, params=params_zip, verify=False, stream=True)
# zipとして保存
if res_zip.status_code == 200:
with open(file_path, 'wb') as f:
for chunk in res_zip.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
f.flush()
return file_path_dic
def get_zip_path(quart_dir_path,securities_dir_path,company_df):
'''取得したいデータファイルパスのリストを返す'''
dir_path_dic = {'四半期報告書':quart_dir_path,'有価証券報告書':securities_dir_path}
file_path_dic = {'四半期報告書':[],'有価証券報告書':[]} # ダウンロードした有価証券報告書のパスを格納する辞書
# 会社コードリストを取得
company_list =list(company_df['EDINETコード'])
for key in dir_path_dic.keys():
# すでにzipをDLしている場合のため、既存のdocIDリストを取得
files = os.listdir(dir_path_dic[key])
existing_file_list = [file for file in files if os.path.isfile(os.path.join(dir_path_dic[key], file))]
file_path_dic[key] = [os.path.join(dir_path_dic[key], file) for file in existing_file_list if file.split('.')[0].split('_')[1] in company_list]
return file_path_dic
def zip_to_df(file_path_dic):
'''ダウンロードしたzipをdfに変換して各会社のdicにして返す'''
all_df_dic = {}
for key in file_path_dic.keys():
print(f'{key}データの変換を開始')
df_dic = {}
for i,company_zip in enumerate(file_path_dic[key]):
# 進捗表示
if i % 100 == 0:
print(f'{i}ファイル目を開始')
company_name = os.path.splitext(os.path.basename(company_zip))[0].split('_')[0]
edinet_code = os.path.splitext(os.path.basename(company_zip))[0].split('_')[1]
doc_name = os.path.splitext(os.path.basename(company_zip))[0].split('_')[2]
if edinet_code not in df_dic:# 会社コードが辞書中に存在しない場合
df_dic[edinet_code] = {}
df_dic[edinet_code] = read_xbrl_from_zip(company_zip)[0]
elif edinet_code in df_dic:# 会社が辞書中に存在する場合
df_dic[edinet_code] = pd.concat( [df_dic[edinet_code],read_xbrl_from_zip(company_zip)[0]])
all_df_dic[key] = df_dic
return all_df_dic
def pickup_shareholder(all_df_dic,company_df):
'''社長の持ち株比率を取得'''
company_df = company_df.set_index('EDINETコード')
company_df['社長名'] = np.nan
company_df['最大株主'] = np.nan
company_df['社長持ち株比率%'] = 0
for company in list(company_df.index):
if company in all_df_dic['有価証券報告書'].keys():
# 必要な有価証券報告書を抽出
securities = all_df_dic['有価証券報告書'][company]
new_securities = securities[securities['提出日'] == max(securities['提出日'].unique()) ]#最新の有価証券報告書のみを抽出
# 株主名簿を取得
NameMajorShareholders = [name.replace('\xa0','').replace('\u3000','').replace('\n','').replace(' ','') for name in list(new_securities[new_securities['tag'] == 'NameMajorShareholders']['値'])]
# 株主の保有率を取得
share_no = [no for no in list(new_securities[new_securities['tag'] == 'NameMajorShareholders']['context'])]
# 各株主のshare ratioを取得
share_ratio_list = []
for no in share_no:
share_ratio_list.append(float(new_securities[(new_securities['context'] == no) & (new_securities['tag'] == 'ShareholdingRatio')]['値']) *100)
# 社長の名前を取得
securities = all_df_dic['有価証券報告書'][company]
temp = [name.replace('\xa0','').replace('\u3000','').replace('\n','').replace(' ','') for name in list(new_securities[(new_securities['context'] == 'FilingDateInstant')&(new_securities['tag'] == 'TitleAndNameOfRepresentativeCoverPage')]['値'])]
if not temp:
temp = list(new_securities[(new_securities['tag'] == 'NameInformationAboutDirectorsAndCorporateAuditors')]['値'])
if temp:
title_name = temp[0].replace('\xa0','').replace('\u3000','').replace('\n','').replace(' ','')
else:
title_name = None
else:
title_name = temp[0]
# 社長の持ち株比率を取得
for i,(name, ratio) in enumerate(zip(NameMajorShareholders,share_ratio_list)):
if i == 0:
company_df.loc[company,'最大株主'] = name
if title_name:
company_df.loc[company,'社長名'] = title_name
if title_name.endswith(name):
company_df.loc[company,'社長持ち株比率%'] = ratio
else:
pass
return company_df
# main部分----------------------------------------------------------------------
# コードリスト
code_company_df = pd.read_csv('EdinetcodeDlInfo.csv',header=1)
code_company_df = code_company_df.rename({'証券コード':'コード','提出者名':'会社名'},axis=1)
code_company_df = code_company_df[code_company_df['上場区分'] == '上場']
code_company_df['コード'] = code_company_df['コード']/10
# 欲しい会社リスト
sbi_df = pd.read_csv('screener_result_小売り.csv')
# 集計用データフレーム
company_df = pd.merge(sbi_df,code_company_df[['コード','会社名','EDINETコード']],on='コード',how='left')
# 取得期間の設定:直近n日分
delta_day = 500
end = date.today()
start = date.today() - timedelta(days=delta_day)
# ダウンロードしたデータのフォルダパス
quart_dir_path = r'四半期報告書保存先パス'
securities_dir_path = r'有価証券報告書保存先パス'
# XBRLデータの取得
list_dic = get_list(start,end,company_df)
# zipのダウンロード
file_path_dic = get_zip(list_dic,quart_dir_path,securities_dir_path)
# 既存ファイルの読み込み
file_path_dic = get_zip_path(quart_dir_path,securities_dir_path,company_df)
# XBRLからデータ形式を変換
all_df_dic = zip_to_df(file_path_dic)
# 持ち株比率を取得
company_df2 = pickup_shareholder(all_df_dic,company_df)

コメント