
投資を行う中でのポートフォリオにおける資産配分は重要な問題です。
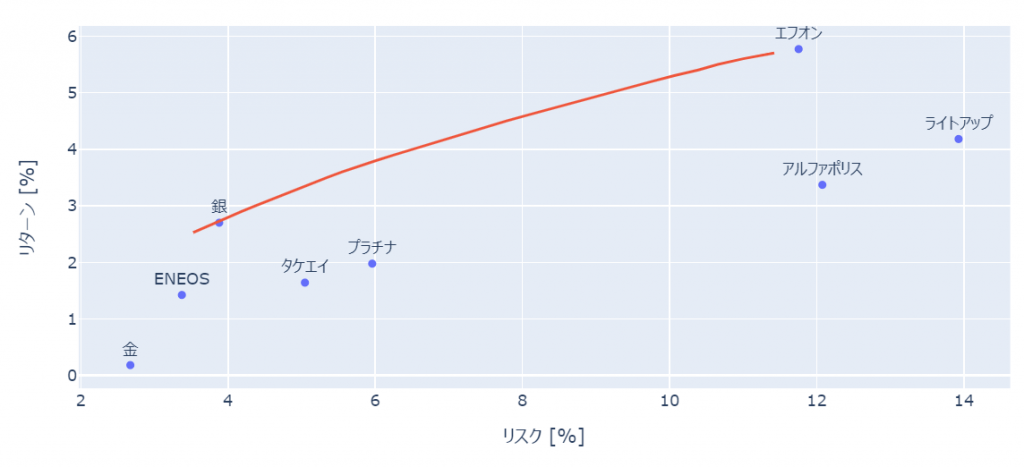
株などの資産の価格変動に伴うリスクとリターンから、あるリスクの時最大のリターンを得るための、ポートフォリオをプロットした曲線を効率的フロンティアといいます。
今回は、pythonのパッケージであるPyPortfolioOptを使用して、株の価格データから効率的フロンティアを求めた際の内容を紹介します。
PyPortfolioOptのインストール
pipでインストール可能です。
windowsの場合にはC++実行環境を導入する必要があるようです。
pip install PyPortfolioOptC++実行環境でVisual Studioを使用する場合には以前の記事を参照してください

価格データの入手
以前の記事で紹介した銘柄をベースに、効率的フロンティアの計算を実施してみます。
pandas_datareaderを使用して、株価データを取得します。
import pandas_datareader as pdr
import pandas as pd
# リスト: ライトアップ、エフオン、アルファポリス、タケエイ、ENEOS、金、プラチナ、銀
symbols = ['6580.jp','9514.jp','9467.jp','2151.jp','5020.jp','1540.jp','1542.jp','1541.jp']
company_list = ['ライトアップ','エフオン','アルファポリス','タケエイ','ENEOS','金','プラチナ','銀']
# 価格データの取得と整形(終値だけ使用)
pdr =pdr.stooq.StooqDailyReader(symbols=symbols, start='2/11/20', end='1/8/21').read().sort_values(by='Date',ascending=True)
all_df = pdr['Close']
all_df.columns = company_list
all_df.head()
価格取得の詳細等に関しては以前の記事を参考してください。

各株の内容の確認
PyPortfolioOptの使用に対しては余談ですが、各株価の内容は以下のような感じになっています。
import seaborn as sns
import matplotlib.pyplot as plt
sns.set(font='Yu Gothic')
# 可視化用コード
# 価格推移
plot_df = all_df/all_df.loc['2020-11-02',:]
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
ax.set_ylabel('相対株価')
plot_df.plot(figsize=(10,10),ax=ax)
# 相関係数
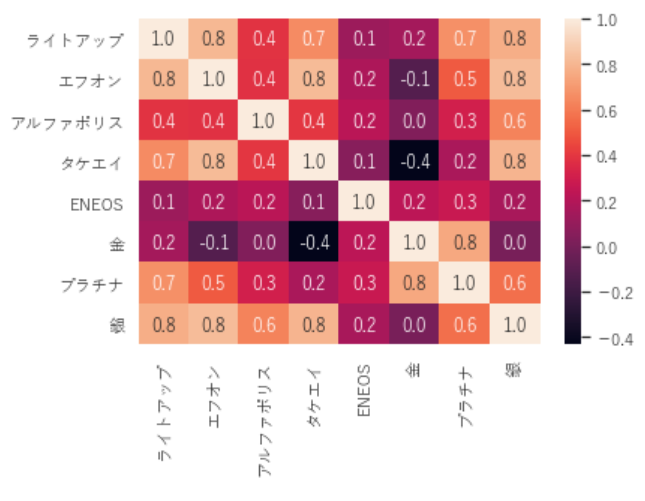
sns.heatmap(all_df.corr(),annot=True, fmt="1.1f")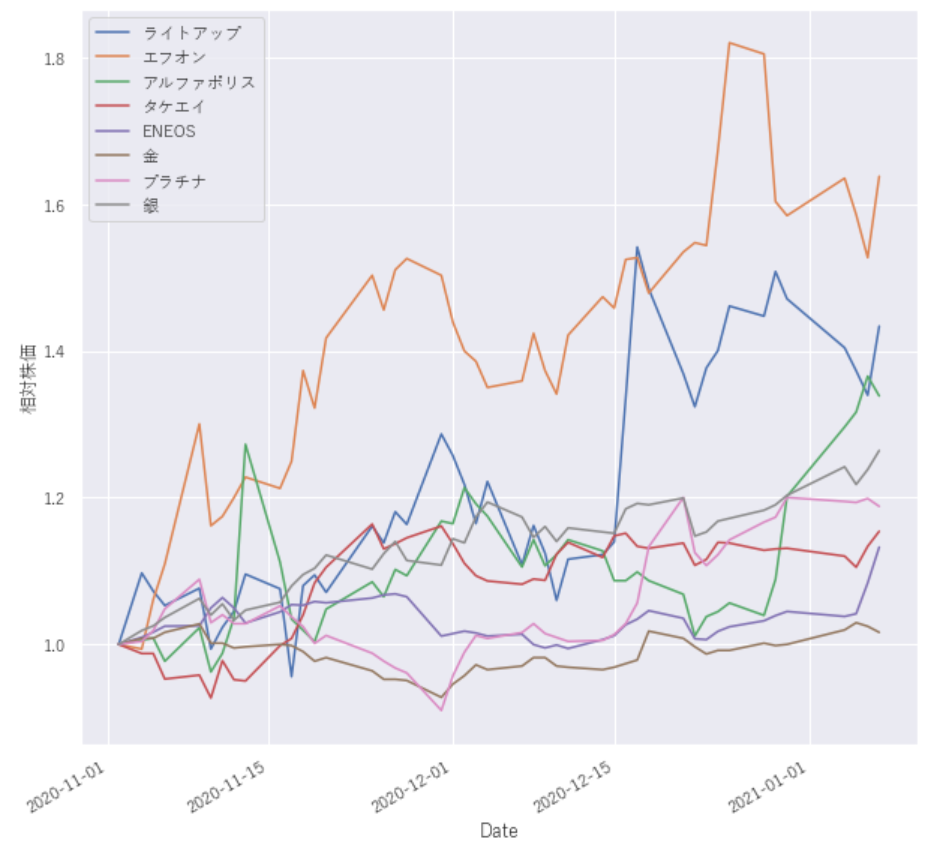
PyPortfolioOptで効率的フロンティアの計算
PyPortfolioOptで効率的フロンティアを計算するには以下のような手順になるようです。
- 価格データの用意
- 価格データからリスク・リターンを任意の手法で計算
- 効率的フロンティアの計算
計算と可視化のコード例は以下の通りです。
from pypfopt.efficient_frontier import EfficientFrontier, objective_functions
from pypfopt import risk_models
from pypfopt import expected_returns
from pypfopt import CLA, plotting
days=5 #リターン、リスクの計算期間
mu = expected_returns.mean_historical_return(all_df,frequency=days) # リターンの計算
S = risk_models.sample_cov(all_df,frequency=days) # リスク:標本共分散の計算
cla = CLA(mu, S)
cla.max_sharpe()
cla.portfolio_performance(verbose=True)
ax = plotting.plot_efficient_frontier(cla, showfig=False)
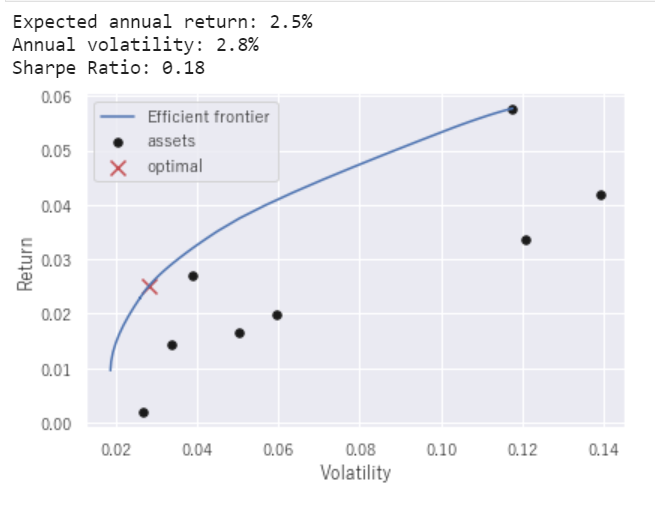
PyPortfolioOptの可視化機能だとイマイチわかりにくいので、plotlyで可視化したコードが以下のような形です。
from pypfopt.efficient_frontier import EfficientFrontier, objective_functions
from pypfopt import risk_models
from pypfopt import expected_returns
import math
import numpy as np
# 諸パラメータの計算
days=5 #リターン、リスクの計算期間
mu = expected_returns.mean_historical_return(all_df,frequency=days) # リターンの計算
S = risk_models.sample_cov(all_df,frequency=days) # リスク:標本共分散の計算
risks = (all_df.pct_change().dropna(how='all')).std() # 各株ごとの平均リスク(標準偏差)の計算
risks = ((risks*risks)*days).apply(math.sqrt) # 指定期間での各株ごとのリスク(標準偏差)の計算
# 銘柄ごとのリスクリターンDFを作成
plot_df = pd.DataFrame()
plot_df['銘柄名'] = mu.index
plot_df['リスク'] = risks.values
plot_df['リターン'] = mu.values
# 効率的フロンティアの計算
ef = EfficientFrontier(mu,S)
trets = np.arange(round(np.amin(mu),3), round(np.amax(mu),3),0.001)
tvols = []
res_ret = []
res_risk = []
weight_df = pd.DataFrame(columns=company_list,index=trets)
for tr in trets:
try:
w = ef.efficient_return(target_return=tr)
w = ef.clean_weights()
pref = ef.portfolio_performance()
res_ret += [pref[0]]
res_risk += [pref[1]]
weight_df.loc[tr,:] = list(w.values())
except:
print(tr,'エラー')
flont_line = pd.DataFrame({'リスク':res_risk,'リターン':res_ret,})
# 可視化
flont_line = pd.DataFrame({'リスク':res_risk,'リターン':res_ret,})
layout = go.Layout(
xaxis = {'title': 'リスク [%]'},
yaxis = {'title': 'リターン [%]',},
)
fig = go.Figure(layout =layout)
fig.add_trace(go.Scatter(x = plot_df['リスク']*100, y = plot_df['リターン']*100,mode='markers+text', text =plot_df['銘柄名'],textposition='top center'))
fig.add_trace(go.Scatter(x = flont_line['リスク']*100, y = flont_line['リターン']*100,mode='lines'))
fig.show()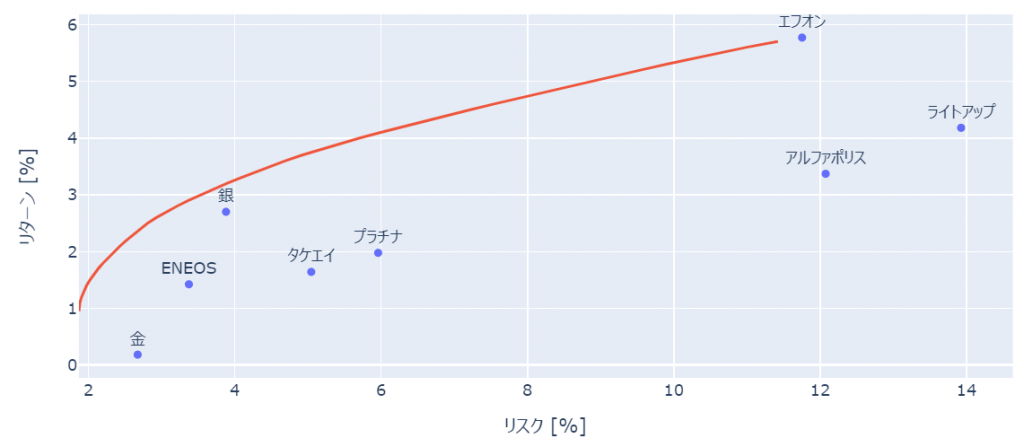
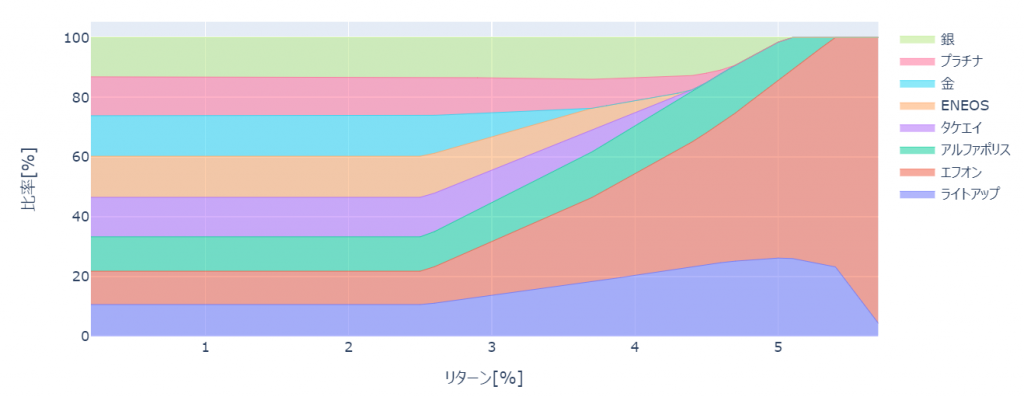
効率的フロンティア上での各リターンを満たすための資産比率は以下のように可視化できます。
layout = go.Layout(
xaxis = {'title': 'リターン[%]'},
yaxis = {'title': '比率[%]',},
)
fig = go.Figure(layout = layout)
for col in weight_df:
fig.add_trace(go.Scatter(
x=weight_df.index*100, y=weight_df[col]*100,
hoverinfo='x+y',
mode='lines',
line=dict(width=0.5,),
name=col,
stackgroup='one' # define stack group
))
fig.show()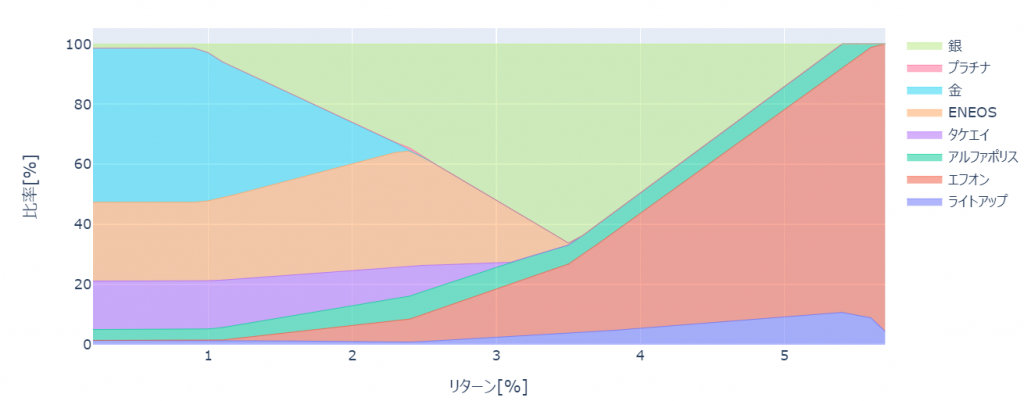
PyPortfolioOptで制限条件付き効率的フロンティアの計算
デフォルトの方法では、資産比率0%になりがちという事で、上下限比率やコスト関数を追加するなどにより、資産比率0%にならないよう方法も実装されているようです。
この場合には、デフォルトの方法と比較して、同リスクの際のリターンが減少していることがわかります。
# デフォルト
ef = EfficientFrontier(mu,S)
# 上下限比率の設定
ef = EfficientFrontier(mu,S,weight_bounds=(0.1,0.5))
# コスト関数の追加
ef = EfficientFrontier(mu, S)
ef.add_objective(objective_functions.L2_reg, gamma=0.1)上下限比率を設定した場合
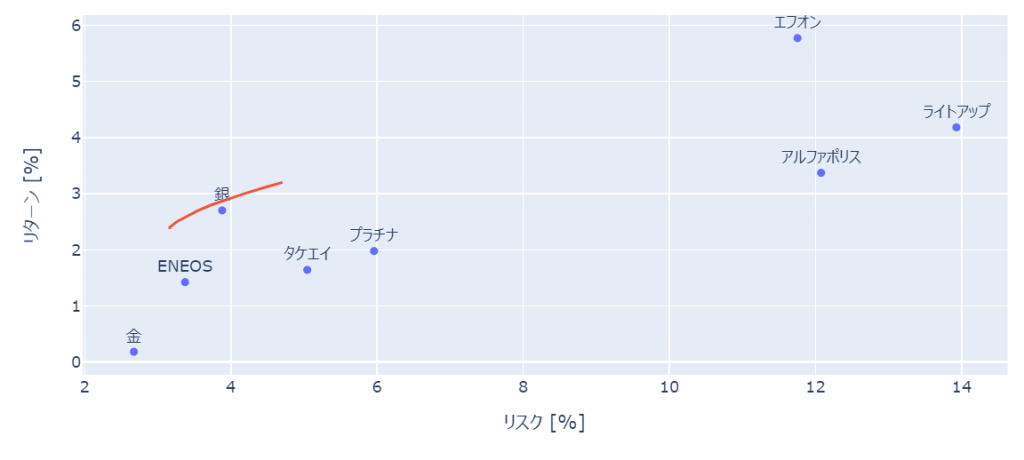
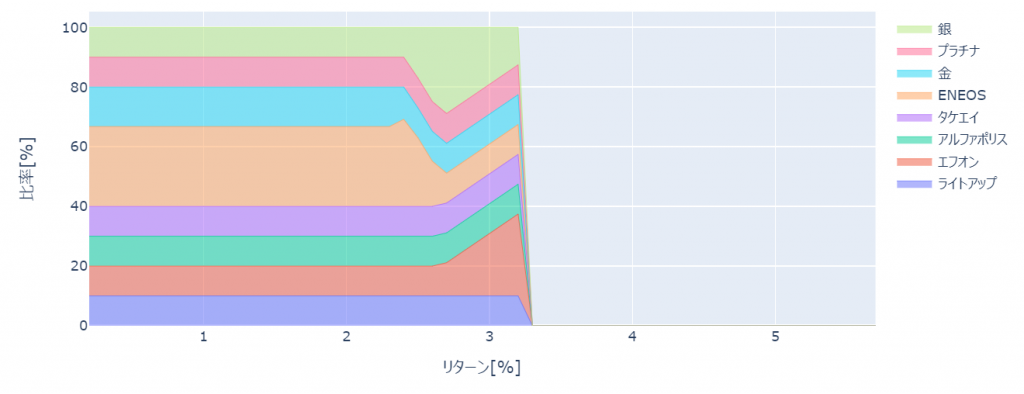
コスト関数を追加した場合
参考



コメント
こんにちは。とても参考になりました。ありがとうございます。
各株価推移の確認で7行目の
plot_df = all_df/all_df.loc[‘2020-11-02’,:]
この日付をいじるとエラーになってしまうのですが原因は何かわかりますか?
コメントありがとうございます。
手元で確認しましたが、問題なく動くようです
エラーの種類が不明ですがkey errorでしょうか?
その場合には、最初に取得した範囲外の日時を指定している
土日などの市場が開いていない日付を指定している
など、データがそもそも存在しないことが考えられます
よろしくお願いします
ありがとうございます。key errorで日付が問題みたいです。
それとplot_df = all_df/all_df.loc[‘2020-11-02’,:]
この1文はどういう意味なのでしょうか?
各株の価格推移を確認するときに株ごとに価格が異なるため、すべての株の株価の推移をグラフ化すると分かりにくくなります。
そこで、任意の日付(今回はdf.loc[‘2020-11-02’,:]で指定している2020年11月2日)からの各株の株価の変化率を求めるというのが
plot_df = all_df/all_df.loc[‘2020-11-02’,:]
の意図です。
行っていることは、指定した日付の株価で他の日付の株価を割って、相対株価に変換しているだけです