
機械学習において、データの偏りが存在する不均衡データでの学習は一般に予測精度が悪くなりがちです。
こういった問題に対処するため、多い方のラベルのデータを減らすアンダーサンプリングや、少ない方のラベルのデータを増やすオーバーサンプリングといったデータ加工が実施される場合があります。
アンダーサンプリングやオーバーサンプリングを実行するための手法としてはSMOTEが有名です。
pythonでこれらの手法が実装されたパッケージとして、imbalanced-learnがあります。
しかし、imbalanced-learnはクラス問題が対象の手法が実装されており回帰問題に対する手法は実装されていないようです。
回帰問題に対応したSMOTEの派生手法としてSMOGNが提案されています。
本記事では、不均衡データにおける回帰問題のアンダー/オーバーサンプリングが実施可能なパッケージsmognの使用方法について紹介します。
インストール
pip install smogn基本的な使用方法
データフレーム形式でのデータと、加工したい列名を与えるだけで実行が可能です。
import smogn
import pandas
import seaborn
# サンプルデータの準備
df = pandas.read_csv('https://raw.githubusercontent.com/nickkunz/smogn/master/data/housing.csv')
# 実行
housing_smogn = smogn.smoter(
data = df, # pandasデータフレーム
y = 'SalePrice' # データ加工を行う列の列名
)実行結果
オリジナルデータは、200000弱のところにデータが集中しています。
加工後のデータは、200000弱の部分では、アンダーサンプリングでデータがカットされています。
一方で、300000当たりのところで、オーバーサンプリングによりデータが増殖されています。
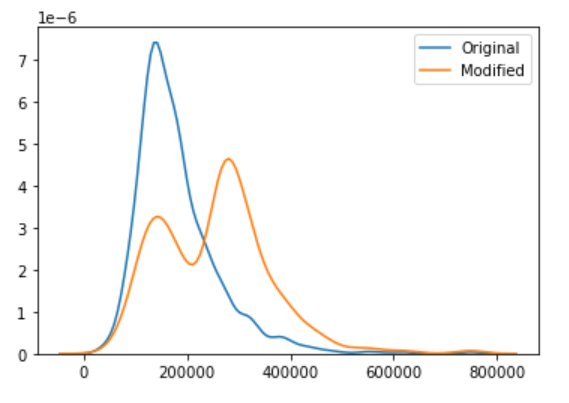
パラメータ変更による分布の操作
smognでは多くのパラメータを設定できますが、ここではパラメータ:rel_cefを変更したときの実行例を紹介します。
import smogn
import pandas
import seaborn
# サンプルデータの準備
df = pandas.read_csv('https://raw.githubusercontent.com/nickkunz/smogn/master/data/housing.csv')
# 実行
housing_smogn = smogn.smoter(
data = df, # pandasデータフレーム
y = 'SalePrice', # データ加工を行う列の列名
# パラメータ
rel_coef = 0.3 # 0以上の実数 初期値1.5
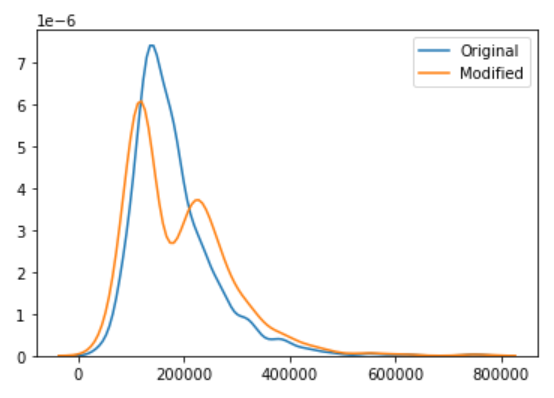
)rel_cef : 0.3 での実行結果
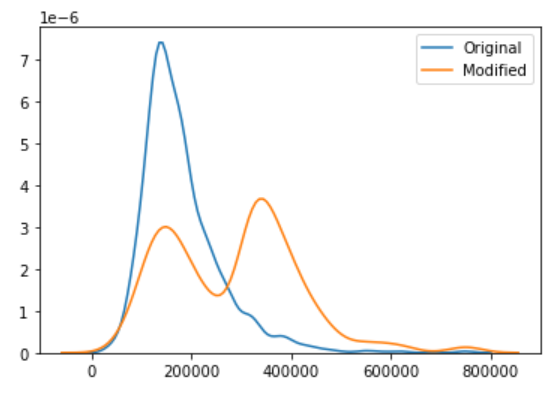
rel_cef : 3での実行結果


コメント