
実験データを一通り眺めてみたい場合、基本的な可視化が簡便にできると便利です。
今回は、pandas profilingというパッケージで、基本的な可視化を簡便に実施する方法を紹介します。
実行環境
環境は、jupyter labとanacondaを使用しています。
環境構築手順は以下を参照ください。

pandas profilingの導入
pandas profilingは以下のようにインストールできます。
GitHub - ydataai/ydata-profiling: 1 Line of code data quality profiling & exploratory data analysis for Pandas and Spark DataFrames.
1 Line of code data quality profiling & exploratory data analysis for Pandas and Spark DataFrames. - GitHub - ydataai/ydata-profiling: 1 Line of code data qual...
github.com
conda install -c conda-forge pandas-profiling可視化のための準備
今回使用するパッケージのインポートとデータは以下の通りです。
csvファイルから実験データを読込み、pandas形式に変換します。
import pandas as pd
# 今回用いるデータ
df = pd.read_csv('exp_data.csv')今回扱うサンプルデータ

pandas profilingを用いたデータの可視化
ProfileReportでpandas形式のデータをpandas profiling用データに変換します。
その後、to_widgetsでjupyter notebook/labに結果を出力します。
項目名に日本語が使用されているとエラーが吐き出されますが、一応可視化はされるようです。
from pandas_profiling import ProfileReport
profile = ProfileReport(df, title='タイトル', explorative=True)
profile.to_widgets()実行すると、以下のように、notebook中に、一連の可視化結果が示されます。
各変数ごとの最大・最小・平均やヒストグラムといった統計情報や、2変数間の散布図や相関係数といった基本的な可視化がタブにごとに表示されます。
over view
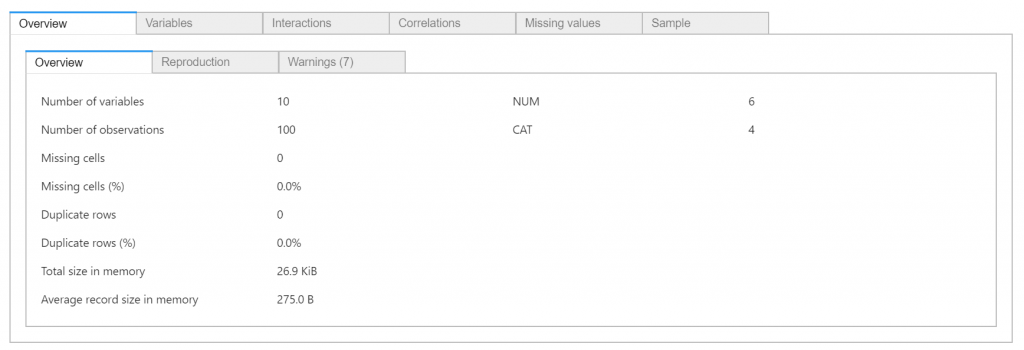
変数ごとの統計値
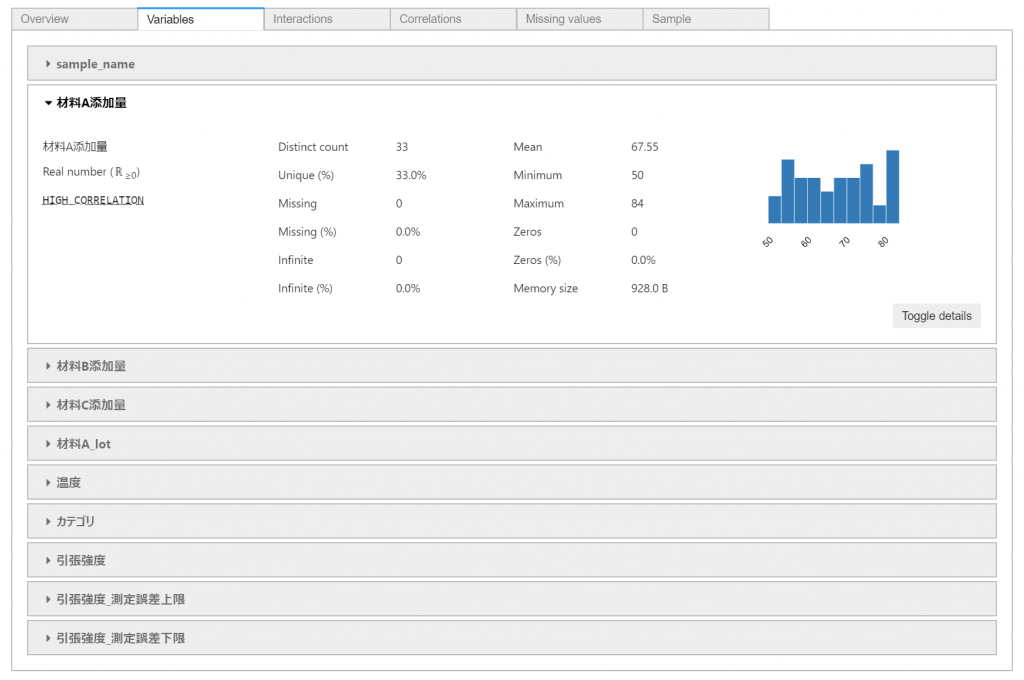
変数間の散布図
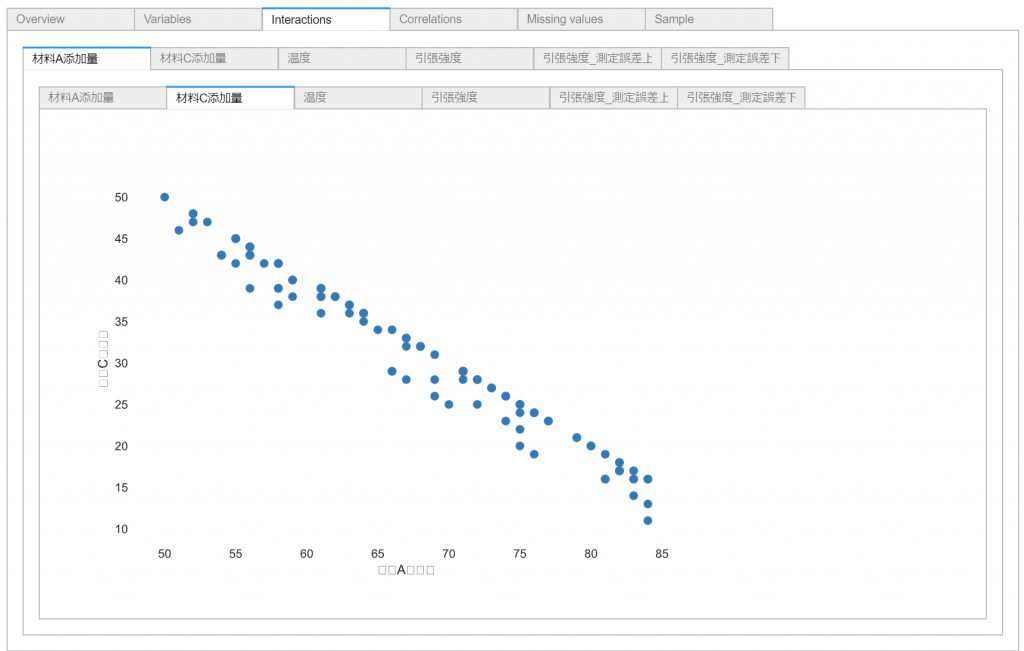
変数間の相関係数
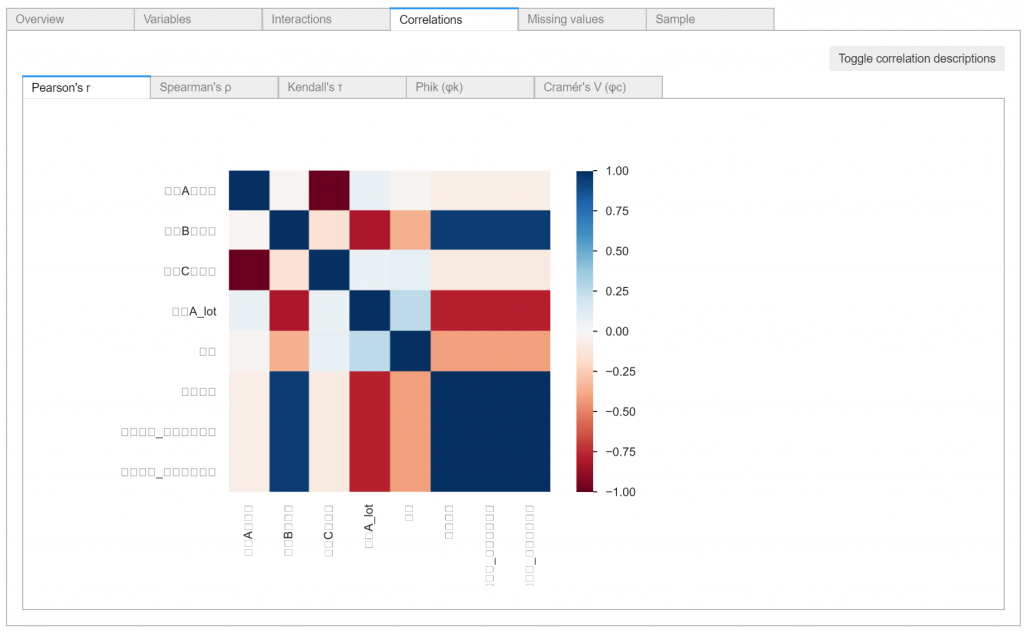
pandas profilingを用いたデータの可視化:HTML出力
以下のように、htmlファイルとしても出力・保存することも可能です。
# notebook中にhtmlとして表示
profile.to_notebook_iframe()
# htmlとして出力
profile.to_file("my_report.html")

コメント