
機械学習行う際には、前処理や交差検証、可視化など様々なことが必要になります。
機械学習に必要なこういった事を1行で実施可能にしたパッケージであるpycaretについての紹介です。
本記事では例として、回帰問題を取り扱っています。
インストール
pip install pycaret準備/前処理
setup()により、データの正規化やカテゴリ変数のエンコーディング、データの分割などの前処理がまとめて行われます。(実施される処理)
setup()の実行結果には、各変数のData Typeや、データの分割結果(デフォルトだと7:3)などが示されます。
from pycaret.regression import *
from pycaret.datasets import get_data
# お試しデータのロード
boston = get_data('boston')
# 前処理
reg1 = setup(data = boston, target = 'medv')お試しデータの概要
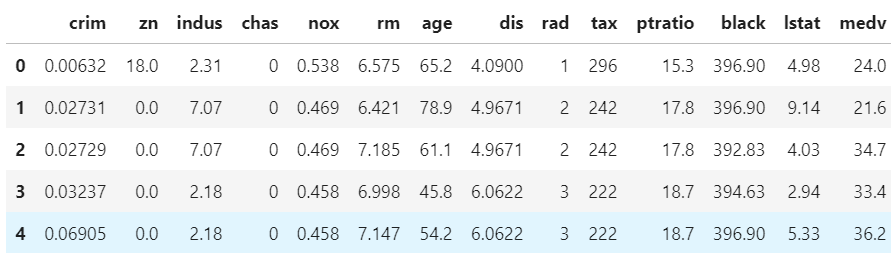
set_upの実行結果

複数モデルの比較
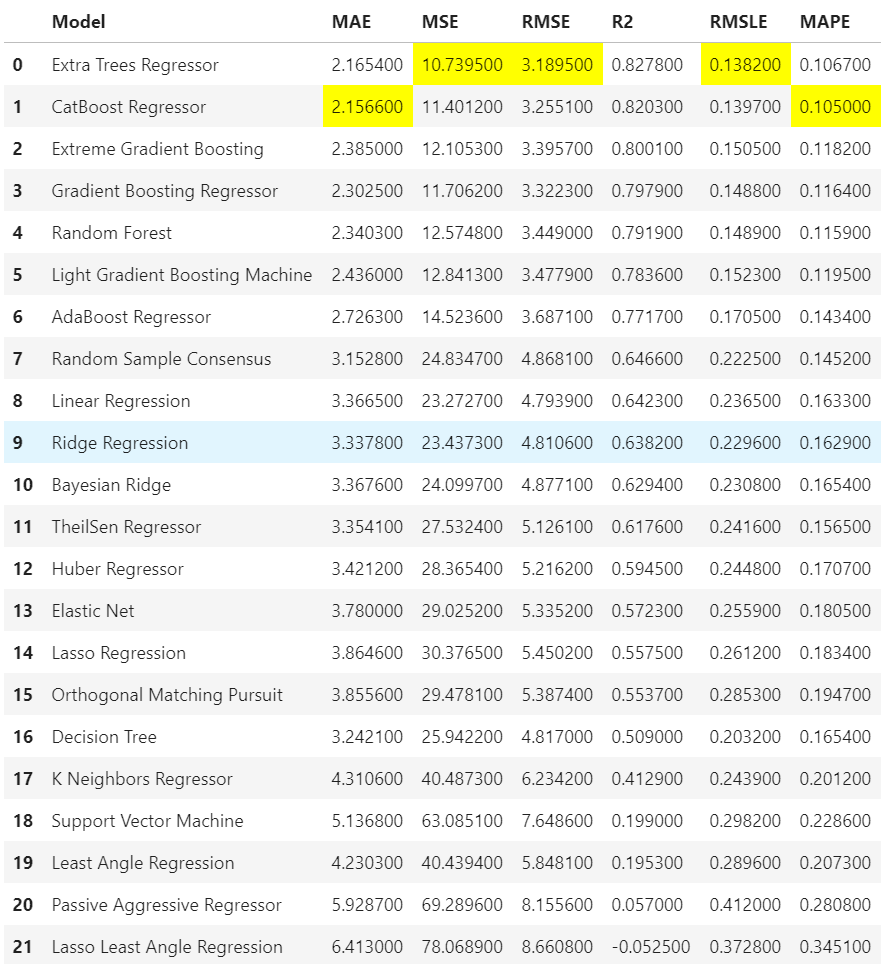
setup完了後に以下のコードで手法ごとのモデル性能の比較を示すことができます。
黄色にハッチングされた部分が最高性能という親切設計です。
手法には、XGBoost(Extreme Gradient Boosting)や LightGBM(Light Gradient Boosting)なども含んでいます。
また、デフォルトだと10分割交差検証での実行結果のようです。
compare_models()手法ごとの予測性能の比較
モデルの構築
任意の手法でモデルの構築は、create_modelに対して手法名を指定することで実施可能です。
各foldおよび平均の予測性能が示されます。
et = create_model('et')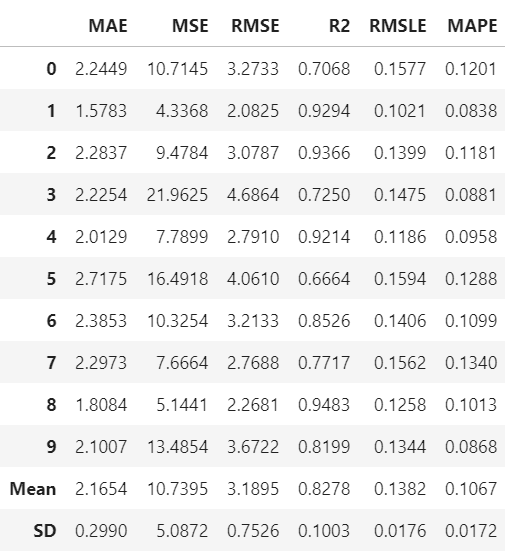
ハイパーパラメータチューニングしたモデルの構築
ハイパーパラメータチューニングしたモデルを得るには以下のように、上記で構築したモデルや最適化指標を指定し、tune_modelで実施可能です。
tuned_et = tune_model(et, n_iter = 50, optimize = 'mae')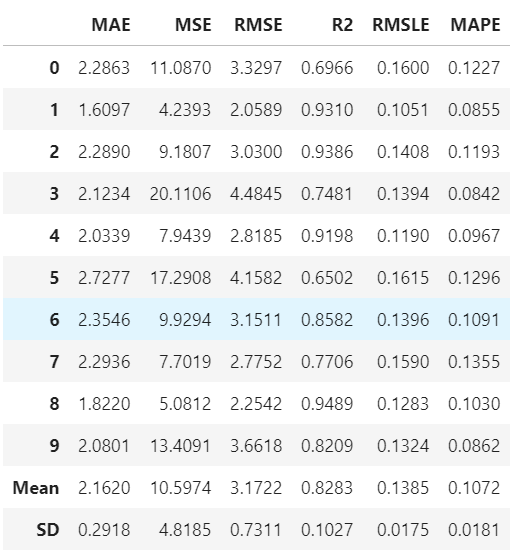
モデルのアンサンブル
モデルのアンサンブル、ブレンド、スタッキングといった事も可能です。
異なる手法のブレンドを行う例を以下に示します。
# 混合するモデルごとにモデル作成
dt = create_model('dt')
catboost = create_model('catboost')
lightgbm = create_model('lightgbm')
# 各モデルのブレンド
blender = blend_models(estimator_list = [dt, catboost, lightgbm])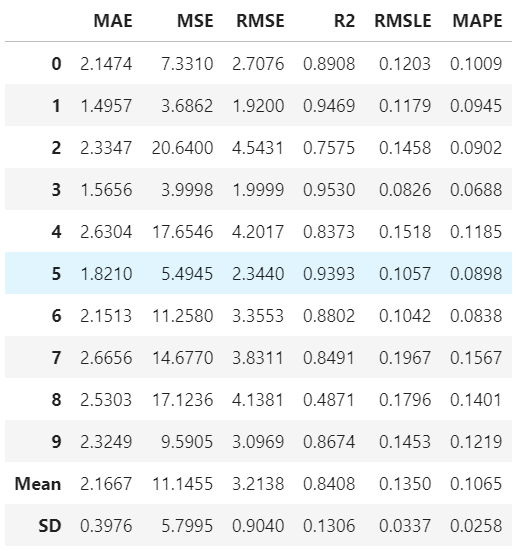
可視化
yyplotや、学習曲線、寄与度などは以下のコードで表示できます。
その他にも色々と表示できるようです。(公式)
plot_model(tuned_et,plot='error')
plot_model(tuned_et,plot='learning')
plot_model(tuned_et,plot='feature')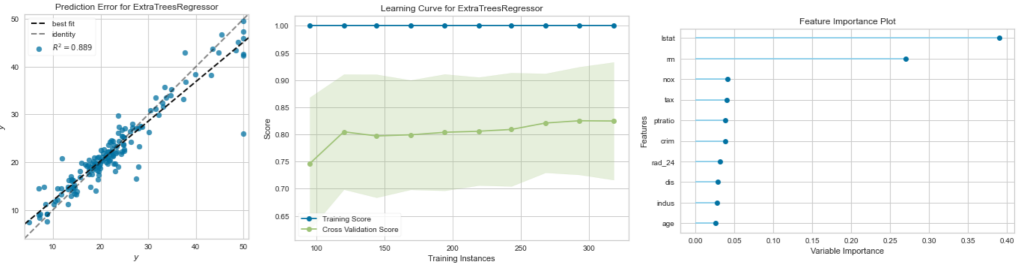
モデルの解釈
決定木系のモデルに関しては、SHAPによるモデル解釈を表示することが可能です。
interpret_model(tuned_et, plot = 'correlation')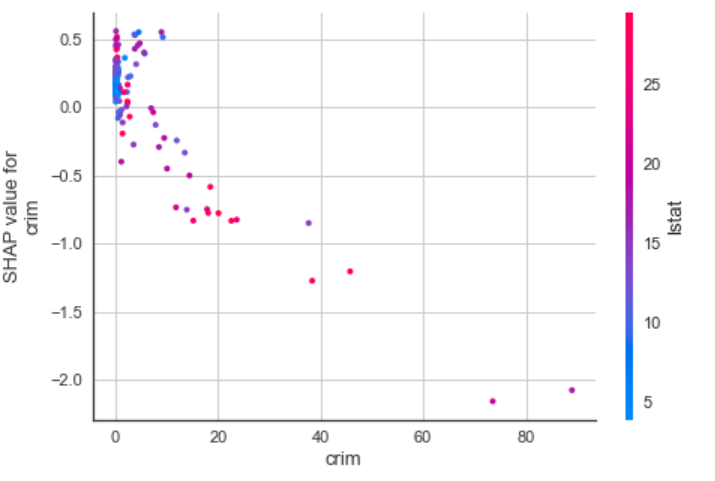
モデルの活用
今回は取り扱いませんが、各パラメータの読み出しやモデルの保存といった事も可能なようです。(公式)
まとめ
きわめて簡単に各手法の比較や可視化などができました。
今後はとりあえずこれを使って試すという事をしてみたいと思います。


コメント