
予測値の不確かさを予測できるとのNGBoostのインストールを行い、実行、不確かさの可視化を行いました。
また、調べたパラメータをまとめてみました。
発表元のスタンフォード大学の論文, github

NGBoost: Natural Gradient Boosting for Probabilistic Prediction
NGBoost: Natural Gradient Boosting for Probabilistic Prediction.
stanfordmlgroup.github.io
GitHub - stanfordmlgroup/ngboost: Natural Gradient Boosting for Probabilistic Prediction
Natural Gradient Boosting for Probabilistic Prediction - stanfordmlgroup/ngboost
github.com
導入
公式通り下記のように導入しました。
pip install --upgrade git+https://github.com/stanfordmlgroup/ngboost.git基本的な使用方法
NGboostのパッケージはsklearnとおおむね同様のインターフェースで使用できます。
NGBoostのパラメータ : 回帰
確率回帰を行うNGBRegressorの各パラメータは以下のようです。
NGBRegressor(
Dist=Normal, # 確率回帰で仮定する確率分布。
Score=LogScore, # 確率的予測値P̂と観測データyを比較するためのルール.
Base=default_tree_learner, # ブースティングアルゴリズムで使用するベース学習器
natural_gradient=True, # 自然勾配の使用の有無
n_estimators=500,
learning_rate=0.01,
minibatch_frac=1.0,
col_sample=1.0,
verbose=True,
verbose_eval=100,
tol=1e-4,
random_state=None
)実装されている確率分布とスコアの組み合わせ
| 確率分布 | パラメータ | スコア |
| Normal:正規分布 | loc , scale | LogScore, : 負の対数尤度, CRPScore |
| LogNormal | s, scale | LogScore, CRPScore |
| Exponential | scale | LogScore, CRPScore |
Base
sklearnの決定木、Ridge回帰が実装されています。
sklearnの回帰モデルを与えて使用することも可能なようです。
default_tree_learner = DecisionTreeRegressor(
criterion="friedman_mse",
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
max_depth=3,
splitter="best",
random_state=None,
)
default_linear_learner = Ridge(alpha=0.0, random_state=None)NGBoostのfitパラメータ : 回帰
NGBoostのfitでは、以下のような機能も使用できます。
sample_weight
ngb = NGBRegressor()
weights = np.random.random(Y_reg_train.shape)
ngb.fit(X_reg_train, Y_reg_train, sample_weight=weights)early_stopping
sample_weightと併せて使用するときはval_sample_weightも設定できるようです。
NGBRegressor().fit(X_reg_train, Y_reg_train,
X_val=X_reg_test, Y_val=Y_reg_test, early_stopping_rounds=10)結果の取得
予測値の取得
ngb = NGBRegressor().fit(X_train, Y_train)
Y_preds = ngb.predict(X_test) # 平均値の予測
Y_dists = ngb.pred_dist(X_test) # 確率分布パラメータの予測
Y_dists.params # サンプルごとの予測値の確率分布パラメータの取得
#{'loc':array([])、
# 'scale':array([])}寄与度の取得
ngb = NGBRegressor().fit(X_train, Y_train)
## 平均値に対するFeature importance
feature_importance_loc = ngb.feature_importances_[0]
## 標準偏差に対するFeature importance
feature_importance_scale = ngb.feature_importances_[1]使用例
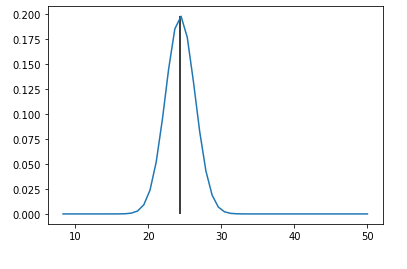
とりあえず実行して、不確かさの可視化を行いました。
予測値の確率分布が出力されています。
from ngboost import NGBRegressor
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
import numpy as np
import matplotlib.pyplot as plt
X, Y = load_boston(True)
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2)
ngb = NGBRegressor().fit(X_train, Y_train)
Y_preds = ngb.predict(X_test)
Y_dists = ngb.pred_dist(X_test)
# test Mean Squared Error
test_MSE = mean_squared_error(Y_preds, Y_test)
print('Test MSE', test_MSE)
# test Negative Log Likelihood
test_NLL = -Y_dists.logpdf(Y_test.flatten()).mean()
print('Test NLL', test_NLL)
# 可視化準備
y_range = np.linspace(min(Y_test), max(Y_test)).reshape((-1, 1))
dist_values = Y_dists.pdf(y_range).transpose()
# データの可視化(noで可視化するサンプルを指定)
no = 8
plt.plot(y_range,dist_values[no])
plt.vlines(Y_preds[no],0,max(dist_values[no]))
plt.show()実行結果
Test MSE 7.73246484357078
Test NLL 2.4126845684258638
参考
公式UserGuide
User Guide
User Guide Welcome to the NGBoost user guide!Details on available distributions, scoring rules, learners, tuning, and model interpretation are ava...
stanfordmlgroup.github.io


コメント