
実験データ(csvやエクセル)ファイルを読込み、データの編集や集計といった加工を行い、ファイルへの書き出しまでをpythonで行う際の基本的な流れについてまとめました。
今回用いるパッケージは以下の通りです。
| 項目 | パッケージ名 |
| csvファイル読込, データ加工 | pandas |
| エクセルファイル読込 | xlwings |
環境構築については以下のリンクを参照ください。

今回作成したNotebook
パッケージのインポート
pandasとxlwingsは以下のようにインポートしておきます。
import pandas as pd
import xlwings as xwデータの読み込み
csvファイルの場合:read_csv(ファイル名)
csvファイルの読み込みはpandasというパッケージを用いて行います。
# csvファイルの読み込んでデータフレーム化
csv_df = pd.read_csv('exp_data.csv')
# 読込んだファイルを表示
csv_df.head()excelファイルの場合
pandasでもエクセルファイルの読み込みや書き出しは可能ですが、ここではエクセル操作用のパッケージであるxlwingsを使用しています。
# エクセルファイルの読み込み
wb = xw.Book('exp_data.xlsx') # エクセルファイルの読み込み
sht = wb.sheets['Sheet1'] # Sheet1のシートを読込み
xl_df = sht.range('A1').expand().options(pd.DataFrame,index=False).value # Sheet1のA1セルを起点とした表の値をデータフレームとして読込み
# 読込んだファイルを表示
xl_df.head()読込み後のデータフレーム
左下図のようなcsvまたはエクセルファイルを、上記の方法で読込むと、どちらの方法でも右下図のような形になります。
なお、下図はデータセットのうちの一部のみを表示しています。
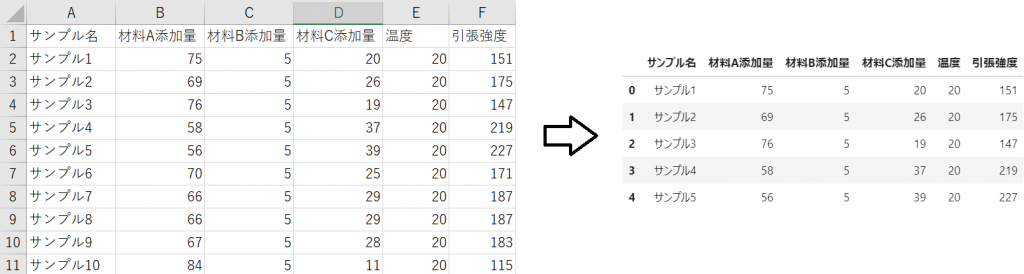
データの書き出し
csvファイルの場合:to_csv(ファイル名)
# csvファイルの出力: to_csv(出力ファイル名)
csv_df.to_csv('output_data.csv')エクセルファイルの場合
# エクセルファイルへの出力
sht.range('A1').options(index=False).value = xl_df # 値を書き込み
wb.save('output_data.xlsx') # ファイルを設定して保存データの追加・削除
新規計算列の追加
追加したい列名(例:計算例)に対して、値を代入すると、最後尾列に新規列が追加されます。
processing_df1 = csv_df.copy() # データを複製して、編集用のデータフレームにする
processing_df1['計算列'] = (processing_df1['材料A添加量'] * processing_df1['材料B添加量'] -5) /2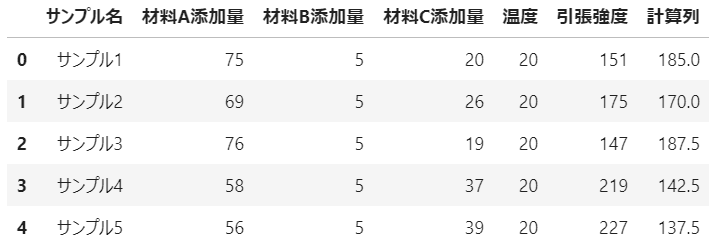
任意の場所に新規計算列の追加:insert(列番号,追加列名,値)
任意の列番号に列を挿入したいときは、insert()を使用します。
processing_df2 = csv_df.copy() # データを複製して、編集用のデータフレームにする
new_data = (processing_df1['材料A添加量'] * processing_df1['材料B添加量'] -5) /2 # 追加する値の計算
processing_df2.insert(5,'計算列',new_data) # 計算列を追加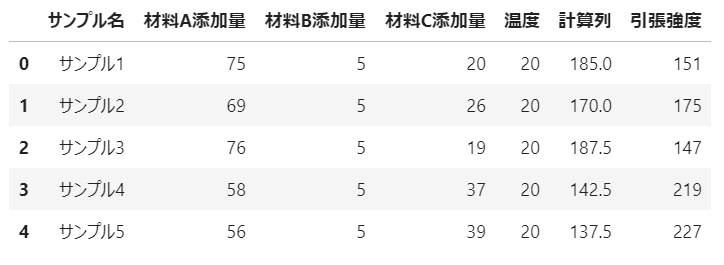
任意行または列の削除::drop(行または列名, axis = 行または列の指定)
drop_df1 = csv_df.drop('引張強度',axis=1) # 列の削除。axis=1は列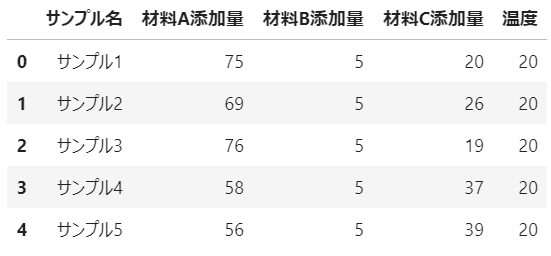
drop_df2 = csv_df.drop(0,axis=0) # 行の削除。axis=0で行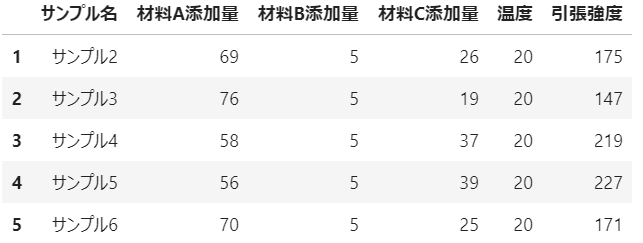
データの抽出
任意の範囲を行列番号で切り出し:iloc[始点行番号:終点行番号,始点列番号:終点列番号]
processing_df3 = csv_df.copy() # データを複製して、編集用のデータフレームにする
processing_df3 = processing_df3.iloc[4:7,3:]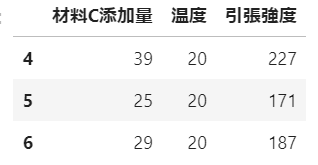
任意の範囲を行列名で切り出し:loc[始点行名:終点行名,始点列名:終点列名]
processing_df4 = csv_df.copy() # データを複製して、編集用のデータフレームにする
processing_df4 = processing_df4.loc[:4,'材料A添加量':'温度']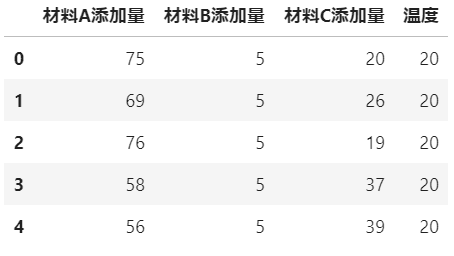
任意の条件の値のデータのみを抽出
cut_df1 = csv_df[csv_df['材料B添加量'] < 2] #材料B添加量が2未満の行だけを抽出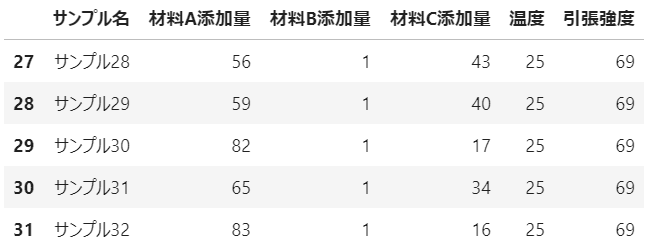
任意の条件の値のデータのみを抽出:複数条件の場合
# 材料B添加量が5未満かつ温度が20より大きい行だけを抽出
cut_df2 = csv_df[(csv_df['材料B添加量'] < 5) & (csv_df['温度'] > 20)]
データの結合
単一のデータファイルだけでなく、異なるデータファイルとデータを結合したい場合があります。
追加の実験データが別ファイルで存在する場合と、
# 追加実験データの読み込み
exp_df2 = pd.read_csv('exp_data2.csv')
別情報が別ファイルに格納されている場合を考えます。
# 別表データの読み込み
add_df = pd.read_csv('add_data.csv')
追加実験データを元のデータに加える: concat([データフレーム1, データフレーム2])
concat_df = pd.concat([csv_df,exp_df2]).reset_index(drop=True) # データを結合して行番号を振りなおす
列の値を元にデータフレームを結合する:merge(データフレーム1, データフレーム2, on=キー列名, how=結合タイプ)
2つのデータファイルに共通の列名をキー列として、ファイルの結合が可能です。
今回の場合では、「サンプル名」をキー列として、同じサンプル名が格納されている行同士を結合します。
結合条件はhowで設定します。
merge_df = pd.merge(csv_df,add_df,on='サンプル名',how='left') # データフレームの結合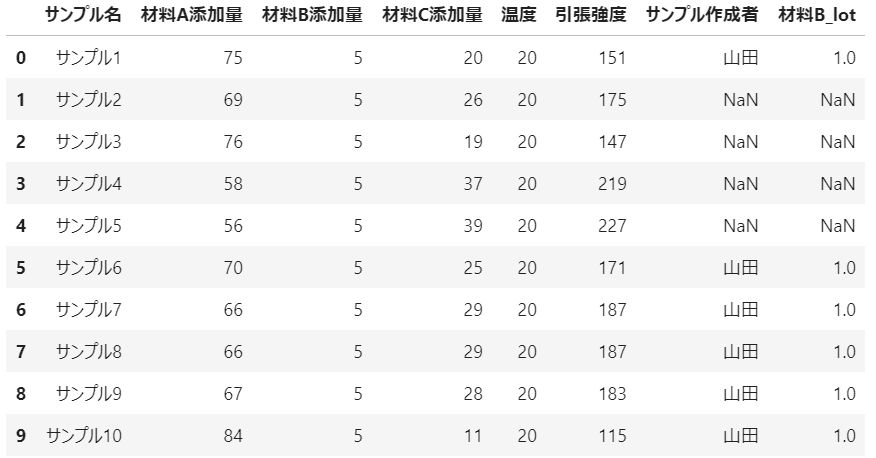
データの集計
サンプル作成者ごとに、各項目の平均値を集計:集計 groupby(集計ラベル列), 平均値計算 mean()
merge_df.groupby('サンプル作成者').mean()
サンプル作成者ごとに、各項目の平均値を集計:表示形式の違う形
merge_df.groupby('サンプル作成者',as_index=False).mean()
サンプル作成者および材料Bのlotごとに、各項目の平均値を集計
merge_df.groupby(['サンプル作成者','材料B_lot']).mean()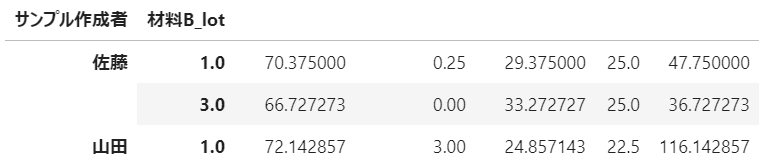
サンプル作成者ごとに、自作の集計を実施
import numpy as np
def return_max(n):
return np.max(n)
merge_df.groupby('サンプル作成者').agg({'材料A添加量': return_max, '材料C添加量':np.min})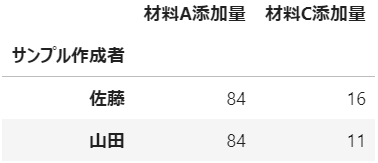

コメント